摘 要:本文围绕科创板拟上市企业估值的研究问题,建立结合指标贡献系数的市场估值模型,解决了市场估值问题与溢价偏差问题;建立灰色关联与多元线性回归模型,解决了指标间定量分析问题与中美差异问题;建立GM-BP预测模型,解决了指标预测和市场估值预测问题;建立隐语义推荐模型,解决了首批上市科创板估值问题。
关键词:灰色关联;多元线性回归;GM-BP预测;隐语义推荐
1 问题概述
对于目前科创板拟上市的公司估值问题,我们基于数学模型与中美股市的现实数据,分四步对问题进行递进式的研究,将整个估值的大问题划分为四个小问题进行逐步攻克,进而最后对于科创板的估值问题进行回答。四个问题分层次分别为:
Q1.根据中美股市数据,计算出 2018 年中国 A 股市场(上证指数成分股)与美国NASDAQ市场的平均市销率作为估值指标,将结果与估计的平均市销率比较,得出估值的溢价或折价。
Q2.建立数学模型,寻找估值指标与基本面指标和流动性指标之间的关系,并分析中美差异。
Q3.通过数学模型预测两个市场的基本面指标和流动性指标,并根据预测结果计算2019年的估值指标。
Q4.结合前文数学模型与数据,预测我国首批科创板企业上市后的估值水平。
2 模型假设
(1)假设不存在股票操纵等违法的事件影响股票的市场价格;
(2)假设短时间内各个上市公司不发生重大变故;
(3)假设平均市销率的计算仅考虑附件中的上市公司;
(4)假设基本面指标和流动性指标仅考虑附件所给指标。
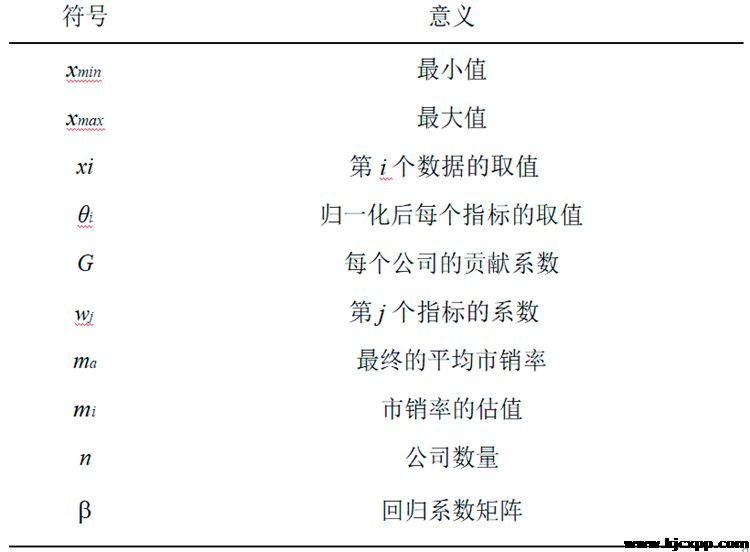
3 符号说明
4 Q1 的求解
4.1 市场估值计算
4.1.1.市场估值模型的构建
针对2018年中国A股市场和美国纳斯达克市场的估值计算,需要综合考虑各公司的市销率数据和基本指标数据。本文结合相关指标数据与市销率估值构建公司贡献系数模型求得最终市场估值。
4.1.2.中国与美国市场估值计算
针对附件数据进行预处理分析,将问题缺失值数据进行剔除。针对每个公司的贡献系数计算中的指标系数,结合相关参考文献与层次分析法进行系数权重判定。最终判定美国公司系数权重比分别为:营业收入权重为0.371,归母净利润权重为0.172,净资产收益率权重为0.132,年成交量权重为0.123, 年平均换手率0.091, 年成交额权重为0.111。中国公司系数权重比分别为:营业收入权重为0.342,归母净利润权重为0.154,净资产收益率权重为0.142,年成交量权重为0.123, 年平均换手率0.107, 年成交额权重为0.132。
最终可得出中国市场估值为4.395,美国市场市估值为3.721。根据结果分析可知,中国市场市销率估值略高于美国,则代表科创板整体表现微差于美国。但二者实际数据值相差不大,也代表着中国市场本身具有较高的潜力。
4.2 市场估值溢价折价水平计算
本文从国泰安数据库和Wind 数据库等相关资料库中获取相关公司的总市值数据。将相关数据代入计算,求得最终中国和美国公司个股估值溢价水平。
针对中国公司估值水平与实际值对比数据进行分析,极个别数据偏差较大之外,例如北汽蓝谷的实际市估率为1.62,而其估值则为698.7274。针对此类异常点数据分析可判断出其可能为出错数据。针对结果进行统计分析,80%的以上数据估计偏差在0.6 以内,由此可得知其本身的估计较为合理。
针对美国公司个股估值水平与实际值对比数据进行分析,极个别数据偏差较大之外,例如ULTRAGENYX PHARMACEUTICAL INC公司实际市估率值为23.2,而其估值则为841.96。但相较于中国个股估计,其估值异常值数据较少。90%的以上数据估计偏差在0.6 以内,由此可得知其本身的估计要较为合理,且美国市场估计具有更高的稳定性。其中,有40%以上的数据估计是一致的。最后,从整体水平来看,其实际水平多数在1.2以下,证明美国科创板的多数公司具有较大的潜力。
5 Q2 的求解
第二个问题需要建立数学模型,定量分析中国A股市场估值指标与基本指标和流动性指标之间的关系。
5.1 基于灰色关联的指标相关性分析
5.1.1.灰色关联模型的建立
本题采用灰色关联分析因变量与各个指标之间的关联系数。灰色关联算法流程步骤如下所示。
Step 1:确定母序列集;
本文主要是金属收得率与其他因素之间的关联。因此本文选定金属收得率为最优指标集,构造其余指标与母序列的关联矩阵。
Step 2:数据的规范化处理;
由于文本指标间可能存在数量级差异,故不能直接进行比较,为了保证结果的可靠性,因此需要对原始文本指标数据进行规范处理。设第k个指标的变化区间为[ jk1 , jk2 ] ,jk1为第k个指标在所有被分析对象中的最小值,jk2为第k个指标在所有被分析对象中的最大值,则可以用下式将上式中的原始数值变成归一化值。可将其表示为:
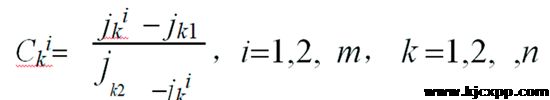
Step 3:相似度系数计算:
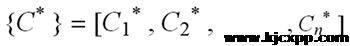
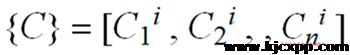
根据灰色系统理论,将 作为参考数列,将作为被比较数列,则用关联分析法分别求得第i个被分析对象的第k个指标与第k个指标最优指标的关联系数,即:
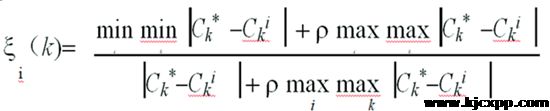
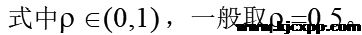
5.1.2.灰色关联结果分析
本文选定估值指标作为母序列,中国A股市场基本面指标和流动性指标作为子序列。将附件一中国A股市场所给数据代入灰色关联向量分析模型,经过Matlab运算分析对相关度进行排序,最终显示排序分别为:年成交量、营业收入、归母净利润、净资产收益率、年平均换手率、年成交额。同理,将附件二美国NASDAQ市场所给数据代入灰色关联向量分析模型,经过matlab运算分析对相关度进行排序,最终显示排序为:营业收入、年成交量、净资产收益率、归母净利润、年成交额。
5.2 中国A股市场和美国NASDAQ市场相关关系结果对比
首先针对中国A股市场和美国NASDAQ市场的估值指标与基本面指标、流动性指标之间的关系分别进行了相关性分析。通过灰色预测进行了分析,为了验证结果的有效性和正确性,应用了多元回归模型对其结果进行验证。得到的中国A股市场和美国 NASDAQ市场的估值指标与基本面指标、流动性指标之间的关系之间存在差异,现在对A股市场和美国NASDAQ市场的估值指标与基本面指标、流动性指标之间的关系之间进行差异分析。
通过对2009年—2012年四年期间的数据进行回归模型的求解得到各个变量的取值,通过对比发现一些现象,比如针对营业收入指标,美国NASDAQ市场的权重比较中国A股市场的权重要大一些。这说明对于美国,营业收入指标对平均市销率的评估影响较大。
6 Q3 的求解
6.1 基于 GM-BP 预测的指标预测分析
6.1.1.灰色预测模型构建
下面对灰色预测模型的构建过程进行详细描述。
Step 1:作数据一阶累加,形成数据序列
设时间序列 X (0)有
通过累加生成新序列 则GM(1,1)模型相应的灰微分方程为:
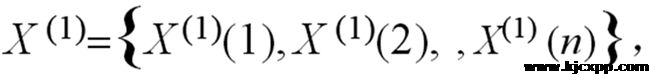

其中:α为发展灰度,μ为内生控制灰度。
Step 2:求参数α和μ。设δ为待估参数向量,

利用最小二乘法求解可得:
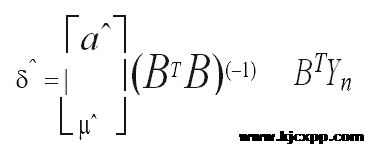
Step 3:建立生成数据序列模型求解微分方程,即可得到预测模型:
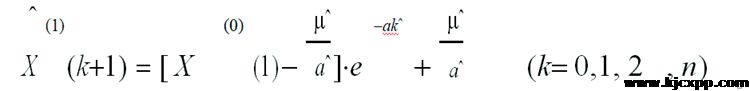
Step 4:建立原始数据序列模型,即由累减生成原始数据序列的模拟序列值:
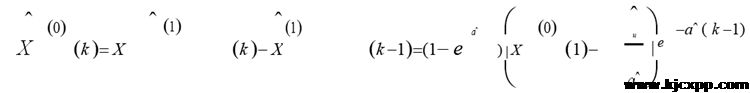
6.1.2.指标数据结果预测
将各指标数据代入原始预测模型进行分析,在Matlab开发环境下对数据进行预测。由于文章篇幅有限,选取苹果公司的营业收入进行预测,随着年份的增长,营业收入也在增长,其呈现一定的规律,2019年的预测结果和之前年份的营业收入大致可以拟合在一条线上,预测效果较好。
6.1.3.基于GM-BP的改进指标预测
由于数据量较大且其相关关系复杂,因此其符合神经网络的训练效果条件。本文在灰色预测的基础上采用神经网络对灰色预测进行改进,以前6 年的数据作为输入,后5年的数据作为期望输出进行训练。针对原始数据65%的样本作为训练样本,35%的样本作为测试样本。根据迭代误差和精度误差分析可知,模型具有较好的训练效果,证明模型本身具有较高的可靠性。
6.2 基于多元回归分析的市场估值指标计算
根据以上的 GM-BP预测模型,解决了指标预测和市场估值预测问题。根据多元回归方程计算出市场估值指标,得到结论如下,美国和中国2019年市场整体估值分别为4.432和3.824,所有预测指标相对残差和级比残差均小于1,验证了模型具有很好的可靠性。
7 Q4 的求解
最后一个问题研究的是我国首批上市科创板的估值问题。本文拟采用如下方法,利用前文构建的灰色预测求出2019年93家企业的基本面数据,通过构建隐语义推荐模型得出企业最佳推荐企业列表,从而得到企业流动指标数据。最后,我们将 2019年指标数据整合,结合美国市场估值回归模型和市场估值计算模型得出上市估值水平。
7.1 基于隐语义推荐模型的公司匹配
7.1.1隐语义推荐模型
隐语义模型的本质便是通过隐含的特征将用户和项目联系起来。根据隐语义模型的思想,可以对股票和股票等级类型两个部分在K维潜在特征空间上进行描述。
本文假设每一起股票的发生是相互独立的,O 为所有发生股票的数据集合,则其似然概率可表示为:
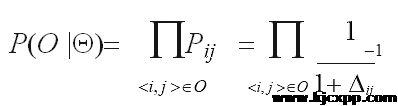
其次,应用贝叶斯公式并假设服从于均值为 0,方差为的高斯先验分布可得后验概率:
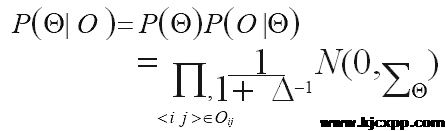
根据取对原则本文将目标函数进行处理,得到优化目标函数:
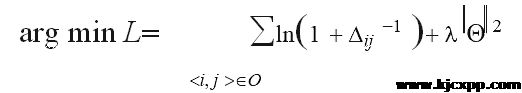
最后,本文将上文建立的Aij公式带入目标函数,得到最终的目标函数为:
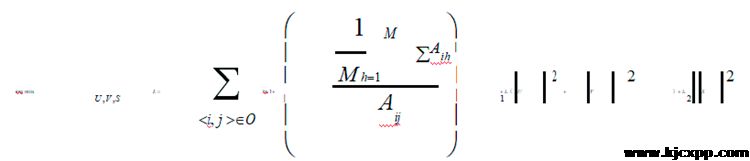
其中, 为正则项(表示二范数),是正则化系数,用于控制参数的复杂程度。
7.1.2基于梯度下降算法的模型求解
首先,利用前文构建的灰色预测求出2019年93家企业的基本面数据,通过构建隐语义推荐模型得出企业最佳推荐企业列表,采用梯度下降算法求解之后得到最终的推荐结果,也即股票的相关度较大的匹配结果。
通过隐语义推荐模型的运用,以及梯度下降算法的求解,得到最终的股票公司匹配方案。通过该方案,我们发现,乐鑫科技和盛屯矿业之间的匹配度已经达到了0.771。这说明在某些方面,两个公司的特征较为相似,可以采用盛屯矿业的历史数据对乐馨科技的2019年的估值进行预测。
7.2 首批科创板企业上市后估值水平预测结果
本文中搜集了2016—2018年基本面指标,结合GM-BP预测 2019年基本面数据。选择部分预测结果进行可视化分析如图8.1 所示。针对流动性指标数据,对结合匹配结果,根据中国A股市场的流动性指标对我国首批科创板企业上市后的流动性指标进行预测。运用美NASDAQ市场的估值量化模型和指标预测结果对最终的估值进行预测和计算。
运用以上的流动性指标和基本面指标预测结果,基本面指标包括年度营业收入、年度归母净利润、年度净资产收益率,流动面指标包括年成交量、年平均换手率和年成交额。运用美国NASDAQ市场的估值量化模型进行计算,得到我国首批科创板企业上市后的估值水平为4.219。
8 研究结论
本文针对指标相关关系求解,并构建灰色关联分析模型对模型进行检验,增加了本文内容的可靠性。针对预测问题,本文构建了GM-BP预测模型,同时对预测结果进行预测精度的检验,该模型在预测结果的精度表现出更高效的效果。最后,本文采用隐语义推荐模型得出企业最佳推荐企业列表从而得到企业流动指标数据。该方法创新性较大,且针对大量数据问题具有较好的可靠性。
参考文献
[1]叶佩娣. 市盈率估值法和市销率估值法在我国 A 股市场的应用分析[J]. 山东财政学院学报, 2008(2).
[2]王薇. 我国创业板市场市盈率估值的合理性分析[J]. 西安财经学院学报, 2010, 23(3):66-70.
[3]高燕. 股票市场市盈率估值指标浅析——我国证券市场板块市盈率的时间序列分析
[J]. 中国物价, 2008(7):20-23.
[4]杜森. 中国股票市场市盈率估值和影响因素研究[D]. 河北经贸大学, 2011.
[5]周星洁. 市盈率估值模型的投资应用分析[J]. 温州职业技术学院学报, 2005, 5(1).
责编/马铭阳
